Building a High-Performance RAG Pipeline
A RAG (Retrieval-Augmented Generation) pipeline seamlessly fuses the precision of information retrieval with the creativity of generative AI, transforming fragmented data into meaningful, human-like responses. By blending smart document processing, vector embeddings, and real-time evaluations, it delivers scalable, intelligent, and adaptive AI-driven solutions for dynamic user interactions.
TECHNOLOGY
2/3/20252 min read
In the AI-driven world, Retrieval-Augmented Generation (RAG) is the backbone of intelligent, efficient, and accurate systems. A well-optimized RAG pipeline ensures scalability, precision, and adaptability at every stage. Here's a breakdown of the key components:
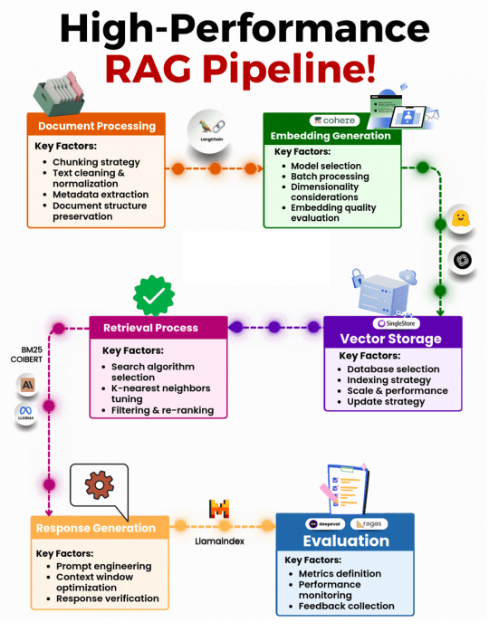
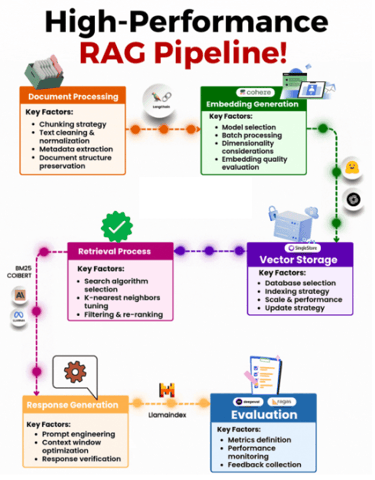
1. Document Processing
Goal: Prepare clean, meaningful text chunks from documents for accurate
embedding.
Key Steps:
Smart Chunking: Maintain overlapping text windows to capture context.
Text Cleaning: Remove noise like HTML tags, special characters, and
unnecessary spaces.
Metadata Extraction: Identify and store relevant metadata.
Example Code for Chunking:
import re
def clean_text(text):
# Remove special characters and multiple spaces
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'[^A-Za-z0-9 .,]', '', text)
return text.strip()
def chunk_text(text, chunk_size=200, overlap=50):
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size - overlap):
chunk = " ".join(words[i:i + chunk_size])
chunks.append(chunk)
return chunks
text = "Your long document content goes here..."
cleaned_text = clean_text(text)
text_chunks = chunk_text(cleaned_text)
print("Generated Chunks:", text_chunks[:2]) # Preview first two chunks
2. Embedding Generation
Goal: Generate high-quality vector embeddings for document chunks.
Key Steps:
Select an embedding model from Cohere, Hugging Face, or OpenAI.
Perform batch inference to improve efficiency.
Evaluate embeddings with cosine similarity or clustering scores.
Example Code Using Cohere:
import cohere
api_key = "YOUR_API_KEY"
co = cohere.Client(api_key)
# Example text chunks
text_chunks = ["This is a sample text.", "Another piece of content for embedding."]
response = co.embed(texts=text_chunks, model="embed-multilingual-v2.0")
embeddings = response.embeddings
print("Embeddings Generated:", embeddings[:2]) # Preview embeddings
3. Vector Storage
Goal: Efficiently store and retrieve document embeddings.
Key Steps:
Use HNSW indexing for approximate nearest neighbor search.
Scale storage using SingleStore or other vector DBs.
Example with Milvus:
from pymilvus import connections, Collection, CollectionSchema, FieldSchema, DataType
# Connect to Milvus
connections.connect("default", host="127.0.0.1", port="19530")
# Define schema
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="vector", dtype=DataType.FLOAT_VECTOR, dim=768)
]
schema = CollectionSchema(fields, description="Embedding storage")
collection = Collection("embeddings", schema)
# Insert data
import numpy as np
data = [[i for i in range(len(embeddings))], embeddings]
collection.insert(data)
print("Data inserted successfully!")
4. Retrieval Process
Goal: Perform fast and accurate searches for relevant document chunks.
Key Techniques:
BM25: Excellent for lexical matching.
ColBERT: Neural retrieval for better semantic understanding.
KNN Tuning: Optimize K values based on benchmark tests.
Example BM25 with Elasticsearch:
from elasticsearch import Elasticsearch
es = Elasticsearch()
# Index sample data
doc = {"content": "AI is transforming industries through advanced models."}
es.index(index="documents", id=1, body=doc)
# Query with BM25
query = {"query": {"match": {"content": "AI models"}}}
response = es.search(index="documents", body=query)
print("BM25 Search Results:", response["hits"]["hits"])
5. Response Generation
Goal: Generate coherent, accurate responses based on retrieved chunks.
Key Steps:
Use LLaMA or other models for generation.
Implement prompt engineering to guide model responses.
Example Prompt Engineering with Hugging Face Transformers:
from transformers import LlamaTokenizer, LlamaForCausalLM
# Load model and tokenizer
tokenizer = LlamaTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf")
model = LlamaForCausalLM.from_pretrained("meta-llama/Llama-2-7b-hf")
# Example prompt
prompt = "Summarize this content: AI is transforming industries through advanced models."
inputs = tokenizer(prompt, return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=50)
print("Generated Response:", tokenizer.decode(output[0], skip_special_tokens=True))
6. Evaluation
Goal: Continuously monitor and improve pipeline performance.
Key Metrics:
Retrieval accuracy (Precision/Recall)
Generation coherence and relevance
Latency benchmarks
Example Using Ragas:
from ragas.metrics import retrieval_precision
# Example evaluation
predicted_results = ["AI transforms industries."]
actual_results = ["AI is transforming industries through models."]
precision_score = retrieval_precision(predicted_results, actual_results)
print(f"Retrieval Precision: {precision_score}")
Final Recommendations
Logging and Monitoring: Set up dashboards using Grafana and Prometheus.
Scalability: Deploy on Kubernetes for scalable microservices.
Continuous Feedback: Incorporate user feedback for system improvements.
Insights
Explore movies, cricket, and technology reviews here.
Connect
Discover
© 2024-26. All rights reserved.